Pandas Data Frame Insert method
The data frame insert method is used to add a new column at the specified position in a data frame.
If a newly added column name already exists then an error occurs.
In order to add a duplicate column, you may use the allow_duplicate= True
Syntax of insert method
DataFrame.insert(loc, column, value, allow_duplicates=_NoDefault.no_default)
An example of the insert to add a new column
For our examples, we have the following data frame created by using this Python program:
Code:
import pandas as pd
inflation_data = {
"Year": [2015, 2016, 2016, 2017],
"Inflation": ['1.75%', '2%', '3%', '3.5%']
}
#Creating a Data frame with two columns
df_inf = pd.DataFrame(inflation_data)
#Display Data Frame
print(df_inf)
Data Frame:
Year Inflation 0 2015 1.75% 1 2016 2% 2 2016 3% 3 2017 3.5%
In the example below, we will only use three arguments in the insert method.
The first argument specifies the position – where to add the column.
It’s a 0-based index, so we provided 2 to add the column after the ID column.
Then we provided the column name and the last argument contains the values for the new column.
Python program:
import pandas as pd
inflation_data = {
"Year": [2015, 2016, 2016, 2017],
"Inflation": ['1.75%', '2%', '3%', '3.5%']
}
#Creating a Data frame with two columns
df_inf = pd.DataFrame(inflation_data)
#Adding a new column at second number in the DF
df_inf.insert(1, "Difference", [0.75, 0.25,1,0.5])
#Display Data Frame with new column
print(df_inf)
Output:
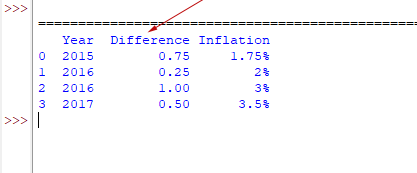
You can see, the Difference column is added after the first column “Year”.
The example of adding a duplicate column
As mentioned earlier, Python will generate an error if you try adding a column name that already exists. See below where we used the insert method for adding a column “Name” in the above-created data frame.
Code:
import pandas as pd
inflation_data = {
"Year": [2015, 2016, 2016, 2017],
"Inflation": ['1.75%', '2%', '3%', '3.5%']
}
#Creating a Data frame with two columns
df_inf = pd.DataFrame(inflation_data)
#Adding a new column at second number that already exist
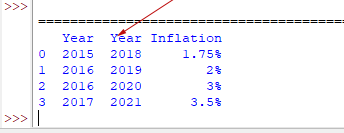
df_inf.insert(1, "Year", [2018,2019,2020,2021])
#Display Data Frame with new column
print(df_inf)
Output:
raise ValueError(f"cannot insert {column}, already exists")
ValueError: cannot insert Year, already exists
So, it generated the ValueError.
Using allow_duplicates in the insert method
In order to allow adding a duplicate column, you may use the allow_duplicates argument as follows:
allow_duplicates = True
See the same example as above and the output.
Code:
import pandas as pd
inflation_data = {
"Year": [2015, 2016, 2016, 2017],
"Inflation": ['1.75%', '2%', '3%', '3.5%']
}
#Creating a Data frame with two columns
df_inf = pd.DataFrame(inflation_data)
#Adding a new column at second number that already exist with allow_duplicates=True
df_inf.insert(1, "Year", [2018,2019,2020, 2021], allow_duplicates=True)
#Display Data Frame with new column
print(df_inf)
Output: