
Merging files of Excel by using Pandas and/or openpyxl
In this tutorial, we will show you how to merge two or more Excel files/sheets by using padas (primarily) and then also using openpyxl(somewhat).
For information, if you don’t know already, Pandas is a Python library for analyzing data, created by Wes McKinney.
Pandas has methods that you can use to work with Excel – including merging files – so let us look at it below section.
An example of merging two files by Pandas
In this example, we will use the concat() method of Pandas. For that, we will specify two files that we want to merge, and a third file is created with the data of both. First, have a look at two files that we will merge:
File 1: test_1.xlsx
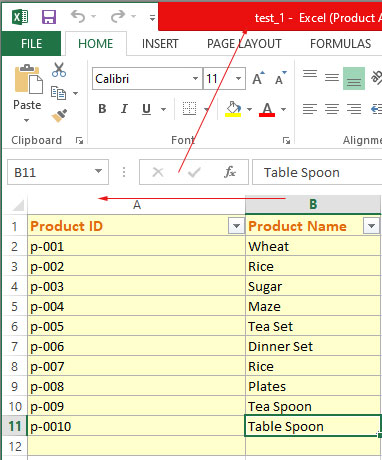
File 2: test_2.xlsx
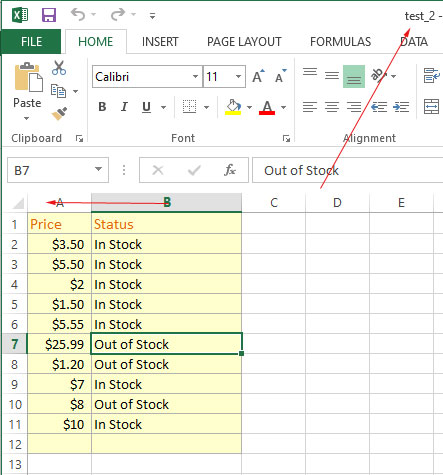
The code to merge two files:
import pandas as panda_merge
# Reading file 1
file_1=panda_merge.read_excel("test_1.xlsx")
# Reading file 2
file_2=panda_merge.read_excel("test_2.xlsx")
# Merging file 1 and file 2 into file 3
#Providing values in iloc is important
file_3=panda_merge.concat([file_1,file_2.iloc[0:,0:]],axis=1)
# creating a new excel file and save the data
file_3.to_excel("test_3.xlsx",index=False)
Output after code execution (File_3.xlsx):
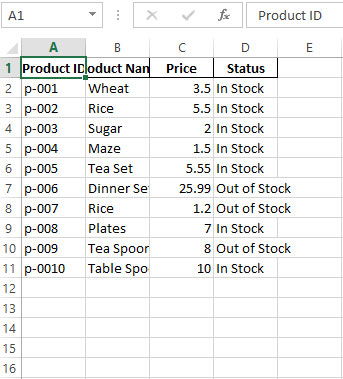
Notice file_2.iloc[0:,0:]] in above code:
- The first 0 represents from which row to merge data from the second sheet.
- The second 0 represents the column of the second file.
See another example below to understand its usage more clearly.
Specifying row and column for the merging file
We will merge only the second column and from the fifth row to the end of the test_2.xlsx file to the newly created test_3.xlsx merged file.
All data from test_1.xlsx will be copied:
The code:
import pandas as panda_merge
# Reading file 1
file_1=panda_merge.read_excel("test_1.xlsx")
# Reading file 2
file_2=panda_merge.read_excel("test_2.xlsx")
#Copying second column only with row from 5th to end
file_3=panda_merge.concat([file_1,file_2.iloc[4:,1:]],axis=1)
# Saving the partial data from two files
file_3.to_excel("test_3.xlsx",index=False)
Result:
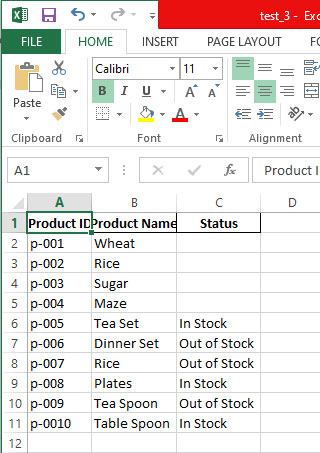
You can see the difference between this merge and the above example.
Second way – Using Pandas/openpyxl for merging sheets
In this way, the Pandas ExcelWriter method is used to merge two or more sheets.
There, we specify openpyxl as the engine.
To understand, this is pandas.ExcelWriter syntax:
class pandas.ExcelWriter(path, engine=None, date_format=None, datetime_format=None, mode=’w’, storage_options=None, if_sheet_exists=None, engine_kwargs=None, **kwargs)
For our example, we have these two Excel Files before merging (Same as in the above example):
File 1: test_1.xlsx
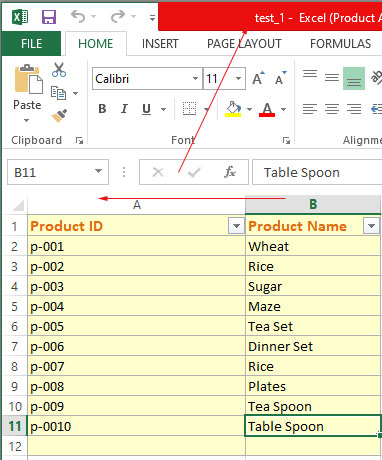
File 2: test_2.xlsx
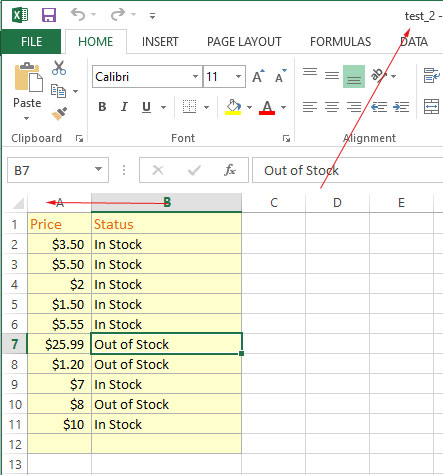
The example below shows using this method for merging two files of Excel:
The code:
import pandas as panda_merge
data_frame=panda_merge.read_excel("test_2.xlsx")
data_frame=data_frame.iloc[:,0:]
with panda_merge.ExcelWriter("test_1.xlsx",mode="a",engine="openpyxl",if_sheet_exists="overlay") as writer:
data_frame.to_excel(writer, sheet_name="My_sheet1",columns=None, startcol=writer.sheets["My_sheet1"].max_column,index=False)
The output after we executed this code:
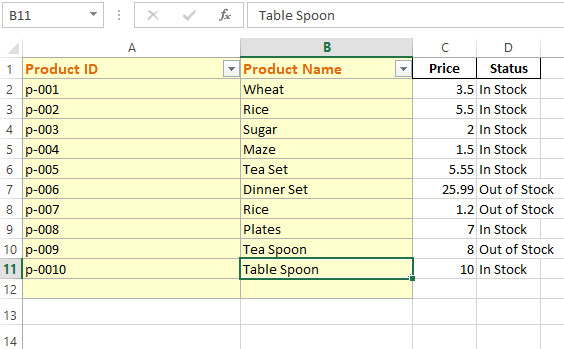
In the code above:
- data_frame reading the test_2.xlsx file – file to be merged.
- This line: data_frame=data_frame.iloc[:,0:] specifies which rows/columns to merge. We specified 0, so both columns will be merged. If we specify 1, only the second column will be merged.
- By using ExcelWriter() method, the test_1 file is opened in the append mode.
- Also notice, we provided the sheet name “My_sheet1”.
Merging only one column/fewer rows by openpyxl and pandas example
Just to show you how to specify rows/cols to merge, see the code below. Only difference is single line i.e. iloc.
See the code and output below:
import pandas as panda_merge
data_frame=panda_merge.read_excel("test_2.xlsx")
#Only merge second column and its last rows after 4
data_frame=data_frame.iloc[4:,1:]
with panda_merge.ExcelWriter("test_1.xlsx",mode="a",engine="openpyxl",if_sheet_exists="overlay") as writer:
data_frame.to_excel(writer, sheet_name="My_sheet1",columns=None, startcol=writer.sheets["My_sheet1"].max_column,index=False)
Result:
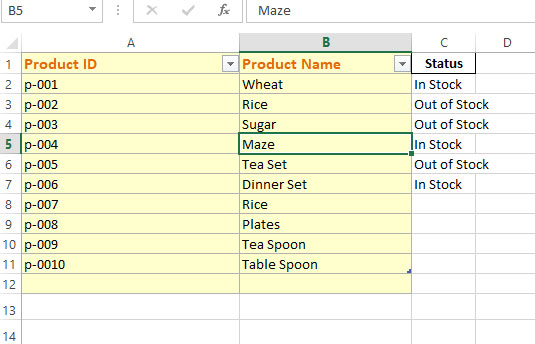
You can see in the above image, only the second column (Status), with rows after 4 are merged.
Notice this line in the above code:
data_frame=data_frame.iloc[4:,1:]
Using pandas.DataFrame.merge method to combine two files
If you have some knowledge of working with databases (MySQL, SQL Server etc.) then this merge type is like a join clause (used in databases).
In that merge method, the join is done at columns or indexes. For example, there should be one common column in both sheets that you want to merge.
Take the example of our sample sheets, if we try to join two files as shown in the above examples:
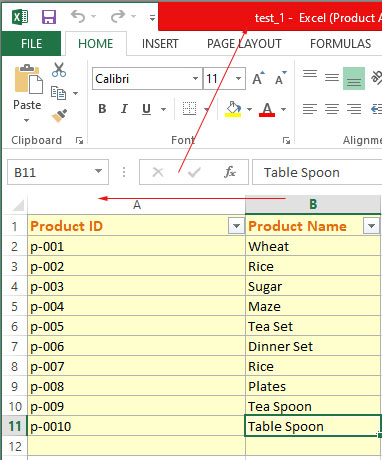
test_1.xlsx
test_2.xlsx
Then pandas.DataFrame.merge will produce an error as there is no common column in both files.
However, for the example, we are adding another column in the test_2.xlsx, i.e. “Product ID”, so it exists in both files to be merged.
After that, these are two files that we will merge by using pandas.DataFrame.merge method:
test_1.xlsx file:
test_2.xlsx file:
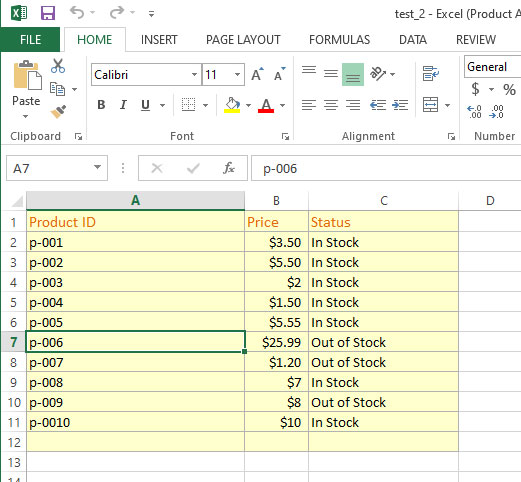
So, you can see that the test_2.xlsx is different than used in the above examples i.e. it contains an additional common column “Product ID”.
Now let us perform a merge of these two files in the third one:
The code:
import pandas as pd_merge
# Taking test_1.xlsx and test_2.xlsx data
d_frame1=pd_merge.read_excel("test_1.xlsx")
d_frame2=pd_merge.read_excel("test_2.xlsx")
# merging both files into data frame
d_frame3=d_frame1.merge(d_frame2)
# Data is saved into a new file - test_3.xlsx
d_frame3.to_excel("test_3.xlsx",index=False)
Result:
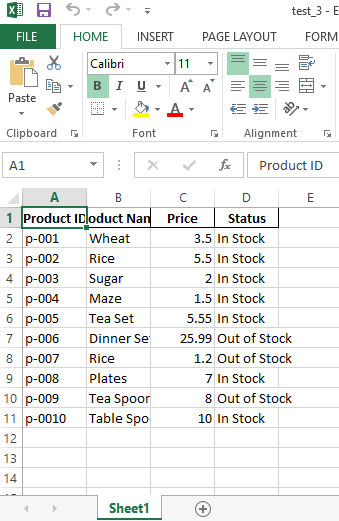
You can see that the resultant new file contains Product IDs only once, and all other columns from the files are included.