What is GROUP BY clause in SQL?
The GROUP BY is a clause in SQL that is used with the SELECT statement for grouping the rows. The purpose is generally performing aggregate operations like SUM, COUNT, AVG, etc. to the group data.
--Simple GROUP BY SELECT emp_name, SUM(emp_sal_paid) As "Total Paid" FROM sto_emp_salary_paid GROUP BY emp_name --With HAVING clause SELECT emp_name, SUM(emp_sal_paid) As "Total Paid" FROM sto_emp_salary_paid GROUP BY emp_name HAVING SUM(emp_sal_paid) >= 5000
A few important points about the GROUP BY clause:
- The SQL GROUP BY is used with the select statement
- If WHERE clause is used in the SELECT statement then GROUP BY is used after it.
- The GROUP BY clause is used before the ORDER BY clause
- The GROUP BY clause is often used with the aggregate functions.
- The column(s) used for grouping data must appear in the SELECT statement.
- You may use one or more columns in the GROUP BY clause for grouping data.
- 1. Syntax of using GROUP BY clause
- 2. A simple example of GROUP BY clause
- 3. Using WHERE clause with GROUP BY query
- 4. Using the HAVING clause in GROUP BY
- 5. The example of using an ORDER BY clause with GROUP BY
- 6. The example of using COUNT and GROUP BY clause
- 7. Using MAX function with GROUP BY example
- 8. Using MIN function example
- 9. The example of using two columns in GROUP BY
- 10. The example of using GROUP BY ROLLUP
- 11. Using GROUP BY CUBE example
Syntax of using GROUP BY clause
SELECT column1, column2, ..., aggregate_function(column) FROM table_name WHERE condition GROUP BY column1, column2, ...;
In the syntax:
| Parameters | Description |
| column1, column2,… | Specify the columns there (separated by a comma) for which you want to group the data. |
| aggregate_function(column) | The aggregate function (e.g., COUNT, SUM, AVG, MIN, MAX) is applied to each group. |
| table_name | The name of the table from which to retrieve data. |
| WHERE | Optional. Specifies the condition for filtering the rows before grouping. |
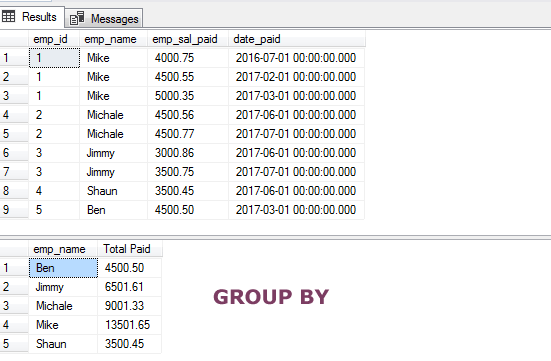
A simple example of GROUP BY clause
For the GROUP BY examples, I will use the sto_emp_salary_paid table that stores the employees’ salaries paid every month. You can see the demo table with data in the graphic below.
The first query simply displays the complete table data and the second query uses the SQL GROUP BY query to get the sum of salary paid to each employee:
Query:
SELECT emp_name, SUM(emp_sal_paid) As "Total Paid" FROM sto_emp_salary_paid GROUP BY emp_name
Using WHERE clause with GROUP BY query
In this example, we set the criteria by using the WHERE clause in the above SELECT statement.
So, we will get the SUM of salaries for the employees who got paid 3500+. The records with less than this value will not be included in the SUM function.
See the query and table output and you may compare the result with the above output:
SQL query:
SELECT emp_name, SUM(emp_sal_paid) As "Total Paid" FROM sto_emp_salary_paid WHERE emp_sal_paid > 3500 GROUP BY emp_name

As mentioned earlier, the GROUP BY clause comes after the Where clause as shown in the above example.
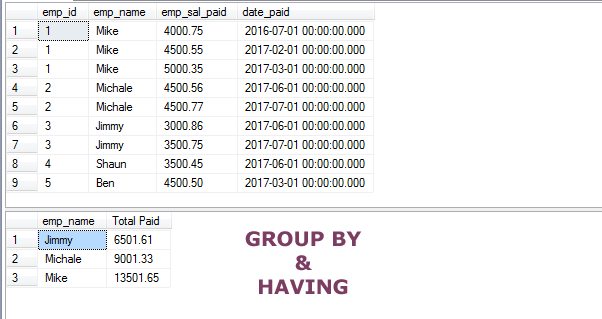
Using the HAVING clause in GROUP BY
Let us say we require the records of those employees whose total paid amount is greater than or equal to 5000.
For that, we may calculate the SUM of each employee and then use a criterion in the SQL HAVING clause.
Query:
SELECT emp_name, SUM(emp_sal_paid) As "Total Paid" FROM sto_emp_salary_paid GROUP BY emp_name HAVING SUM(emp_sal_paid) >= 5000
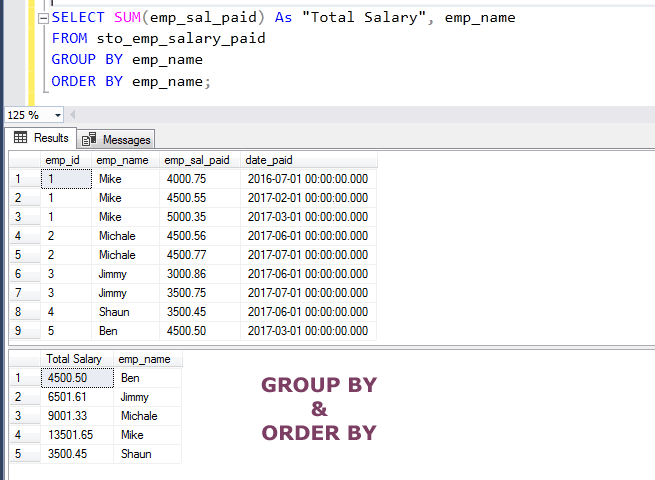
The example of using an ORDER BY clause with GROUP BY
The ORDER BY clause is used to sort the results in ascending or descending order. You may also sort the results fetched after using the SELECT with GROUP BY clause.
The ORDER BY clause is used after the GROUP BY as shown in the query below:
The query:
SELECT SUM(emp_sal_paid) As "Total Salary", emp_name FROM sto_emp_salary_paid GROUP BY emp_name ORDER BY emp_name;
The example of using COUNT and GROUP BY clause
The above examples show using the SUM function with GROUP BY clause. As mentioned earlier, you may use any aggregate function with GROUP BY including the COUNT function.
The following query shows using the COUNT for getting the number of salaries paid to each employee in our example table. Also, I used the ORDER BY clause with the DESC keyword in the same query:
Query:
SELECT COUNT(*) As "No of Salaries", emp_name FROM sto_emp_salary_paid GROUP BY emp_name ORDER BY emp_name DESC;

Using MAX function with GROUP BY example
Let us extend the above example scenario while using the MAX function with the GROUP BY clause. The query will return the total number of salaries for each employee along with the maximum amount paid.
The MAX function is used in the same query; so you may use multiple aggregate functions as well.
Also, for the demo only, I used the ORDER BY clause with two aggregate columns; one with default ASC order and the other with DESC order:
SELECT MAX(emp_sal_paid) As "Maximum Salary",COUNT(*) As "Total Salaries", emp_name FROM sto_emp_salary_paid GROUP BY emp_name ORDER BY MAX(emp_sal_paid), COUNT(*) DESC;
The resultant recordset:

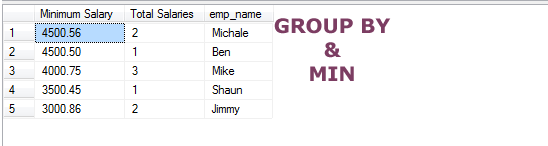
Using MIN function example
Just a little variation in the above query and this example shows using the MIN function with GROUP BY clause:
The Query:
SELECT MIN(emp_sal_paid) As "Minimum Salary",COUNT(*) As "Total Salaries", emp_name FROM sto_emp_salary_paid GROUP BY emp_name ORDER BY MIN(emp_sal_paid) DESC, COUNT(*) ASC;
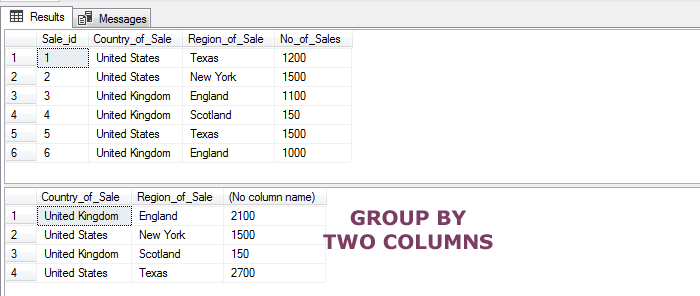
The example of using two columns in GROUP BY
For explaining more than one column usage in the GROUP BY clause, I am going to use the Sales table. The sto_sales table stores the sales based on countries and regions (for the demo only).
In the SELECT – GROUP BY statement, we will get the sum of sales on the basis of:
- Country
- Regions
The query should sum the record where it finds the same Country and Regions, unlike the above examples where data were grouped on the basis of a single column. Have a look:
The two columns query:
SELECT Country_of_Sale, Region_of_Sale,SUM(No_of_Sales) FROM sto_sales GROUP BY Country_of_Sale,Region_of_Sale;
The output:
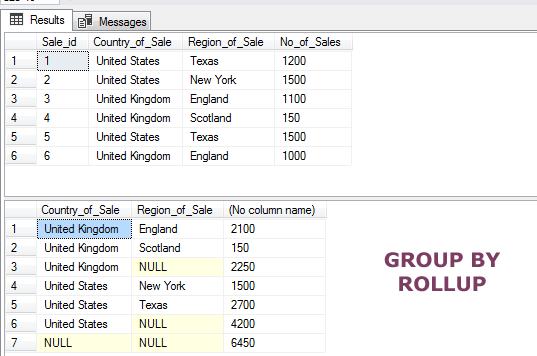
The example of using GROUP BY ROLLUP
The following example shows using the GROUP BY ROLLUP where two columns are specified. By looking at the complete data and records returned by GROUP BY ROLLUP, you will understand how it works:
The Query:
SELECT Country_of_Sale, Region_of_Sale,SUM(No_of_Sales) FROM sto_sales GROUP BY ROLLUP (Country_of_Sale,Region_of_Sale);
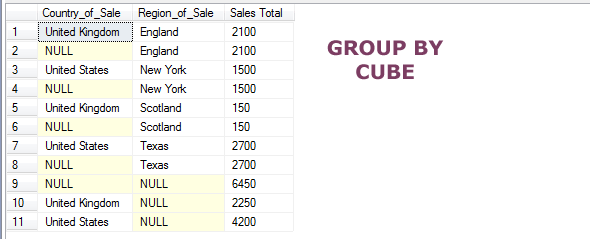
Using GROUP BY CUBE example
The GROUP BY CUBE is used to create groups of all possible combinations of specified columns. This is what the official statement says:
“For GROUP BY CUBE (a, b) the results has groups for unique values of (a, b), (NULL, b), (a, NULL), and (NULL, NULL).”
Have a look at the resultset returned after using it in our demo sales table:
Query:
SELECT Country_of_Sale, Region_of_Sale,SUM(No_of_Sales) As "Sales Total" FROM sto_sales GROUP BY CUBE (Country_of_Sale,Region_of_Sale);
The output: