- Your table may contain duplicate values in a column and in certain scenarios you may require fetching only unique records from the table.
- To remove the duplicate records for the data fetched with the SELECT statement, you may use the DISTINCT clause as shown in the examples below.
--Simple SELECT – DISTINCT SELECT DISTINCT(emp_name) FROM sto_emp_salary_paid; --WHERE clause with DISTINCT SELECT DISTINCT(emp_name) FROM sto_emp_salary_paid WHERE emp_sal_paid >= 4500; --DISTINCT clause with GROUP BY SELECT DISTINCT(emp_name),emp_id, SUM(emp_sal_paid) As "Total Paid" FROM sto_emp_salary_paid GROUP BY emp_name,emp_id;
- The SELECT DISTINCT clause in SQL is used to retrieve unique values from a specified column or set of columns in a table.
- 1. An example of a simple SELECT – DISTINCT
- 2. Using WHERE clause with DISTINCT
- 3. The example of the COUNT function with DISTINCT
- 4. The DISTINCT clause with GROUP BY example
- 5. Using the HAVING clause with DISTINCT
- 6. The DISTINCT clause with ORDER BY example
- 7. Using multiple columns in the DISTINCT clause
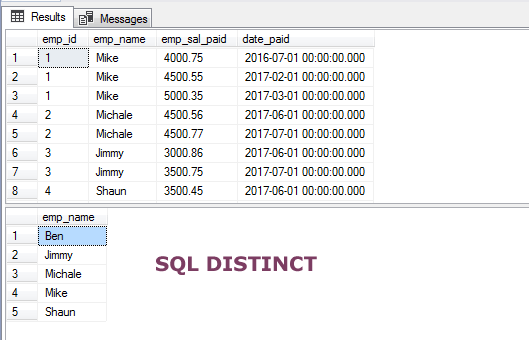
An example of a simple SELECT – DISTINCT
In the first example, I used the DISTINCT clause with a SELECT statement to retrieve only unique names from our demo table, sto_emp_salary_paid.
This table stores employee salaries along with their names. So, the duplicate occurrence of employee names occurs in the table.
By using the DISTINCT clause, we get only unique employee names:
Query:
(Applies to SQL Server and MySQL databases)
Using WHERE clause with DISTINCT
In this example, I used the WHERE clause with SELECT/DISTINCT statement to retrieve only those unique employees whose paid salary is greater than or equal to 4500.
See the query and result set:
Query:
SELECT DISTINCT(emp_name) FROM sto_emp_salary_paid WHERE emp_sal_paid >= 4500;

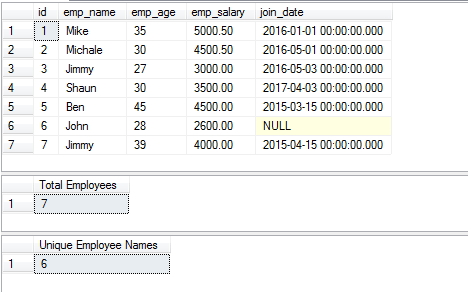
The example of the COUNT function with DISTINCT
You may also use the COUNT SQL function to get the number of records by using the DISTINCT clause. The function returns only count for the rows returned after the DISTINCT clause.
For the demo, I am using an employee table that stores the information about the employees. Three queries are used in the demo as follows:
- The First query returns the complete record from the table
- The second query gets the number of employees by using ID (COUNT and DISTINCT)
- Whereas, the third returns the unique employee names by using emp_name column.
SELECT * FROM sto_employees; SELECT COUNT(DISTINCT id) AS "Total Employees" FROM sto_employees SELECT COUNT(DISTINCT emp_name) AS "Unique Employee Names" FROM sto_employees
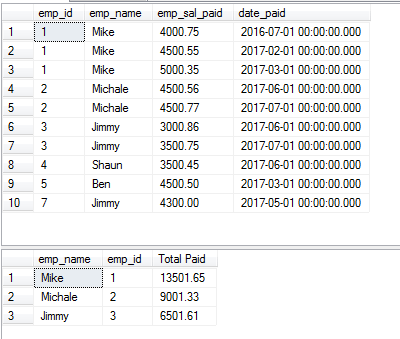
The DISTINCT clause with GROUP BY example
The following query fetches the records from the same table as used in the above examples and groups the employees’ paid salaries. For that, the GROUP BY and DISTINCT clauses are used as follows:
The Query:
SELECT DISTINCT(emp_name),emp_id, SUM(emp_sal_paid) As "Total Paid" FROM sto_emp_salary_paid GROUP BY emp_name,emp_id;
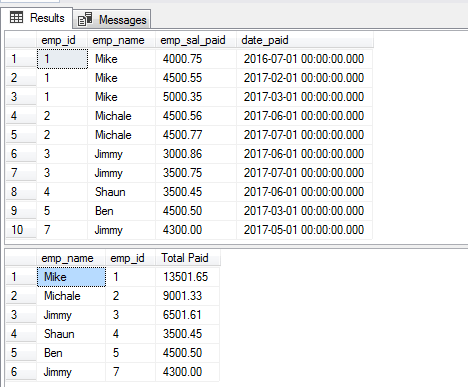
The record for “Jimmy” appears twice as it has two different IDs.
Using the HAVING clause with DISTINCT
As using the GROUP BY clause with DISTINCT, you may also add a HAVING clause for fetching records.
In the following query, the HAVING clause is added in the above example and we will fetch the records whose SUM is greater than 5000.
The query:
SELECT DISTINCT(emp_name),emp_id, SUM(emp_sal_paid) As "Total Paid" FROM sto_emp_salary_paid GROUP BY emp_name,emp_id HAVING SUM(emp_sal_paid) > 5000;
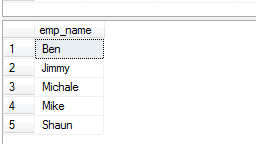
The DISTINCT clause with ORDER BY example
The SQL ORDER BY clause can be used with the DISTINCT clause for sorting the results after removing duplicate values. See the query and output below:
SELECT DISTINCT(emp_name) FROM sto_emp_salary_paid ORDER BY emp_name;
The result:
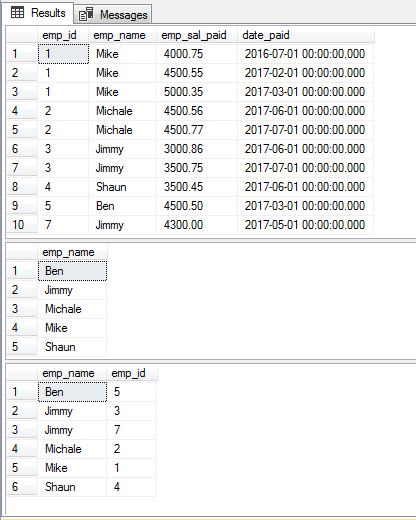
Using multiple columns in the DISTINCT clause
You may also specify two or more columns while using the SELECT – DISTINCT clause. As such, our example table contains duplicate values for employees and their IDs, so it will be good learning to see how the DISTINCT clause returns the records by using both these columns in the single query.
To see the difference, I first wrote a query with DISTINCT (emp_name) which is followed by using both columns:
The Query:
SELECT DISTINCT emp_name FROM sto_emp_salary_paid ORDER BY emp_name; SELECT DISTINCT emp_name,emp_id FROM sto_emp_salary_paid ORDER BY emp_name;
The results for complete table, DISTINCT emp_name and DISTINCT emp_name,emp_id queries: